Code
- 1
- Carga de librerías. Note que es necesario cargar la librería randomForest.
- 2
- Especificación genérica del modelo. La técnica de Random Forest es una variante del método Bagging. En principio, se usan todas las posibles variables explicativas.
Este es un post con código ejecutable que explica el algoritmo de machine learning denominado Random Forest usando el ecosistema tidymodels.
set.seed(1234)
3Boston_part <- initial_split(Boston,prop = 0.80, strata = "chas")
Boston_entr <- training(Boston_part)
Boston_test <- testing(Boston_part)initial_split.
La función randomForest tiene varios argumentos. Uno de los más importantes es mtry. Este hiperparámetro define el número de variables aleatoriamente muestreadas que se constituyen como candidatas en cada particionamiento. En tarea de regresión el valor por defecto es p/3. En clasificación es sqrt(p). En donde p es el número de variables del conjunto de datos original.
4rf_fit <- fit(rf_spec, medv ~ ., data = Boston_entr)augment(rf_fit, new_data = Boston_test) |>
5 rmse(truth = medv, estimate = .pred)# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
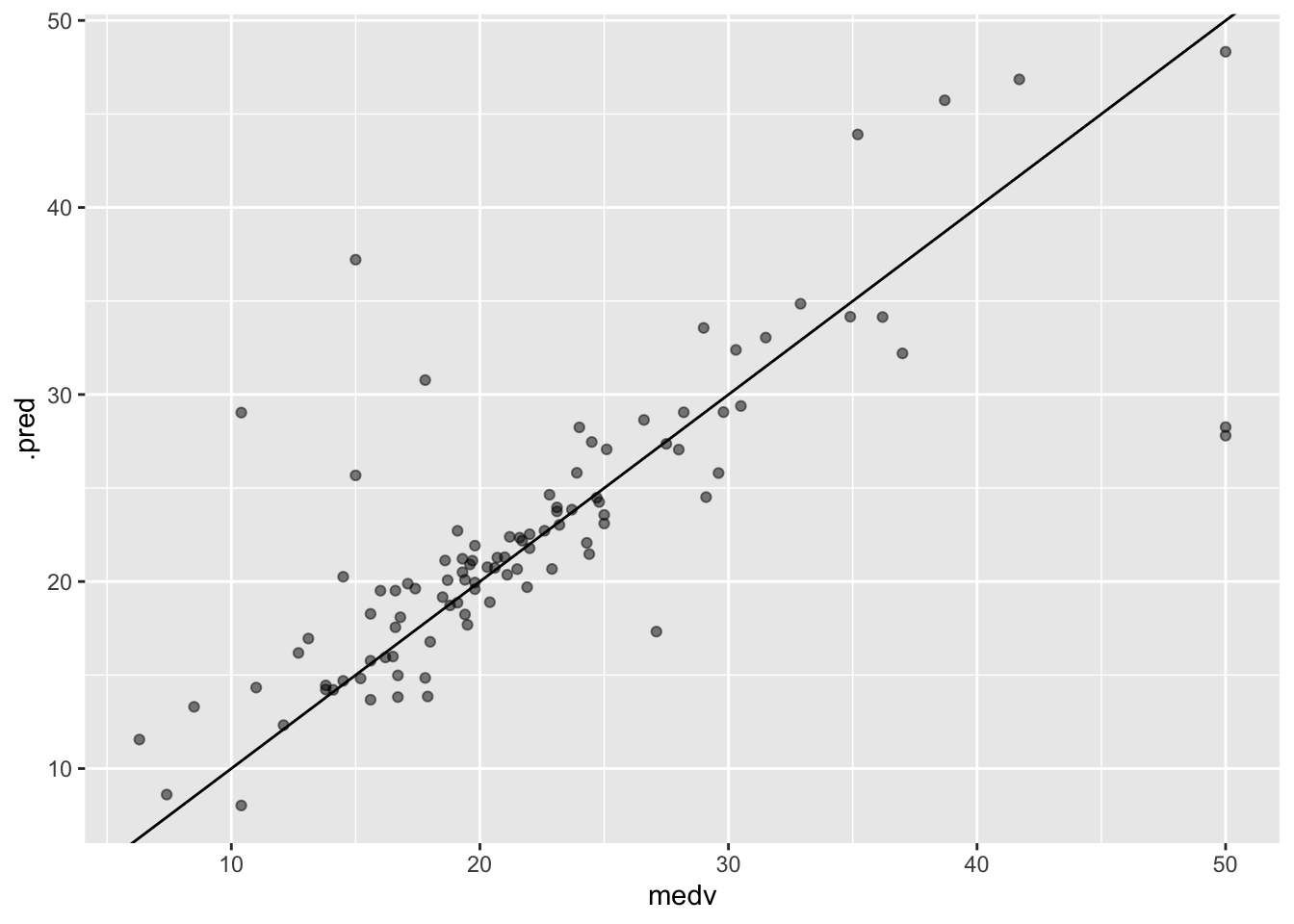
1 rmse standard 5.21augment(rf_fit, new_data = Boston_test) |>
ggplot(aes(medv, .pred)) +
geom_abline() +
geom_point(alpha = 0.5) # <5> Graficación de la estimación